Easier AI
This book aims to show a simpler way to do many things. A repeated result is that learners learn better if they can pick their own training data. By reflecting on what has been learned so far, they can avoid the confusing, skip over the redundancies, and focus on the important parts of the data.
This technique is called active learning. And it can be extraordinary effective. For example, in software engineering (SE), systems often exhibits "funneling": i.e. despite internal complexity, software behavior converges to few outcomes, enabling simpler reasoning. Funneling explains how my imple BareLogic" active learner can build models using very little data for (e.g.) 63 SE multi-objective optimization tasks from the MOOT repository. These tasks are quite diverse and include
- software process decisions,
- optimizing configuration parameters,
- tuning learners for better analytics.
Successful for this MOOT problems results (e.g.) better advice for project managers, better control of software options, and enhanced analytics from learners that are better tuned to the local data.
MOOT includes 100,000s of examples with up to a thousand settings.
Each example is labelled with up to five effects. BareLogic's task is to find the best example(s),
after requesting the least number of labels . To do this,
BareLogic labels N=4 rest examples, then it:
- Scores and sorts labeled examples by "distance to heaven" (where "heaven" is the ideal target for optimization, e.g., weight=0, mpg=max)
- Splits the sort into
sqrt(𝑁)bestand𝑁−sqrt(𝑁)restexamples. - Trains a two-class Bayes classifier on the
bestandrestsets. - Finds the unlabeled example
Xthat is most likelybestvia
argmax(x):log(like(best|X)) - log(log(rest|X)) - Labels
X, then incrementsN. - If
X<Stopthen loop back to step1. Else returnmost(thebest[0]item) and a regression tree built from the labeled examples.
BareLogic was written for teaching purposes as a simple demonstrator of active learning. But in a result consistent with "funneling", this quick-and-dirty tool achieves near optimal results using a handful of labels. As shown by the histogram, right-hand-side of this figure, across 63 tasks:
- eight labels yielded 62% of the optimal result;
- 16 labels reached nearly 80%,
- 32 labels approached 90% optimality,
- 64 labels barely improves on 32 labels,
- etc.
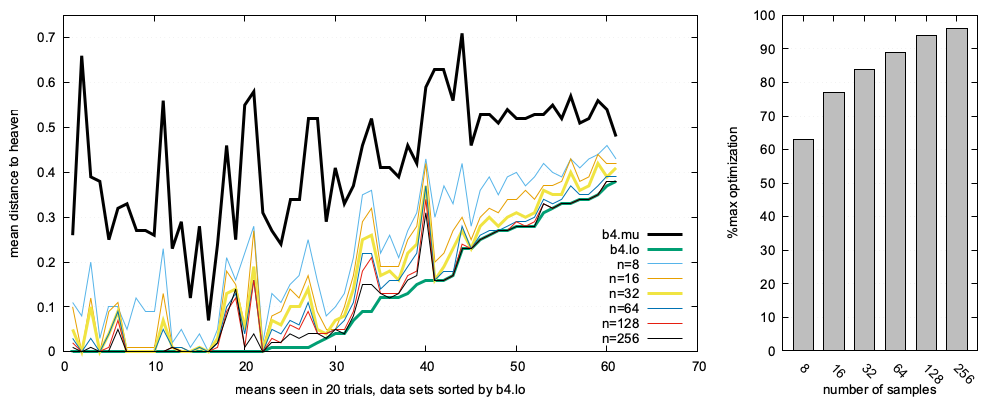 Figure: 20 runs of BareLogic on 63 multi-objective tasks.
Figure: 20 runs of BareLogic on 63 multi-objective tasks. Histogram shows mean (1 − (most − b4.min)/(b4.mu − b4.min)). Most is the best example returned by BareLogic. b4 are the untreated examples. min is the optimal example closest to heaven.
The lesson here is that achieving state-of-the-art results can be achieved with smarter questioning, not planetary-scale computation (i.e. big AI tools like large language models, or LLMs). Active learning addresses many common concerns about AI such as slow training times, excessive energy needs, esoteric hardware requirements, testability, reproducibility, and explainability.
- The above figure was created without billions of parameters. Active learners need no vast pre-existing knowledge or massive datasets, avoiding the colossal energy and specialized hardware demands of large-scale AI.
- Further, unlike LLMs where testing is slow and often irreproducible, BareLogic's Bayesian active learning is fast (e.g., for 63 tasks and 20 repeated trials, this figure was generated in three minutes on a standard laptop).
- Most importantly, active learning fosters
human-AI partnership.
- Unlike opaque LLMs, BareLogic's results are
explainable via small labeled sets (e.g.,
N=32). Whenever a label is required, humans can understand and guide the reasoning. - The resulting tiny regression tree models offer concise, effective, and generalizable insights.
- Unlike opaque LLMs, BareLogic's results are
explainable via small labeled sets (e.g.,
Active learning provides a compelling alternative to sheer scale in AI.
- Its ability to deliver rapid, efficient, and transparent results fundamentally questions the "bigger is better" assumption dominating current thinking about AI.
- It tell us that intelligence requires more than just size.
I am not the only one proposing weight loss for AI.
- The success of LLM distillation (shrinking huge models for specific purposes) shows that giant models are not always necessary.
- Active learning pushes this idea even further, showing that leaner, smarter modeling can achieve great results.
- So why not, before we build the behemoth, try something smaller and faster?